
The multiprocessing.pool.ThreadPool is a flexible and powerful thread pool for executing ad hoc tasks in an asynchronous manner.
In this tutorial, you will discover how to get started using the ThreadPool quickly in Python.
Let’s get started.
ThreadPool Life-Cycle
The multiprocessing.pool.ThreadPool provides a pool of generic worker threads.
It was designed to be an easy and straightforward to use thread-based wrapper for the multiprocessing.pool.Pool class.
There are four main steps in the life-cycle of using the ThreadPool class, they are: create, submit, wait, and shutdown.
- 1. Create: Create the thread pool by calling the constructor ThreadPool().
- 2. Submit: Submit tasks synchronously or asynchronously.
- 2a. Submit Tasks Synchronously
- 2b. Submit Tasks Asynchronously
- 3. Wait: Wait and get results as tasks complete (optional).
- 3a. Wait on AsyncResult objects to Complete
- 3b. Wait on AsyncResult objects for Result
- 4. Shutdown: Shutdown the thread pool by calling shutdown().
- 4a. Shutdown Automatically with the Context Manager
The following figure helps to picture the life-cycle of the ThreadPool class.
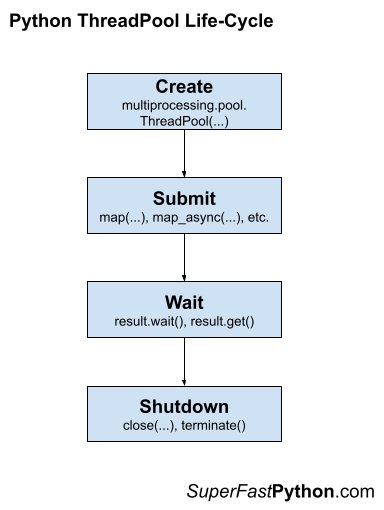
Let’s take a closer look at each life-cycle step in turn.
Run loops using all CPUs, download your FREE book to learn how.
Step 1. Create the Thread Pool
First, a multiprocessing.pool.ThreadPool instance must be created.
When an instance of a ThreadPool is created it may be configured.
The thread pool can be configured by specifying arguments to the ThreadPool class constructor.
The arguments to the constructor are as follows:
- processes: Maximum number of worker threads to use in the pool.
- initializer: Function executed after each worker thread is created.
- initargs: Arguments to the worker threads initialization function.
Perhaps the most important argument is “processes” that specifies the number of worker threads in the thread pool. It is named for the number of processes in the multiprocessing.pool.Pool class, although here it does refer to the number of threads.
By default the ThreadPool class constructor does not take any arguments.
For example:
|
1 2 3 |
... # create a default thread pool pool = multiprocessing.pool.ThreadPool() |
This will create a thread pool that will use a number of worker threads that matches the number of logical CPU cores in your system.
For example, if we had 4 physical CPU cores with hyperthreading, this would mean we would have 8 logical CPU cores and this would be the default number of workers in the thread pool.
We can set the “processes” argument to specify the number of threads to create and use as workers in the thread pool.
For example:
|
1 2 3 |
... # create a thread pool with 4 workers pool = multiprocessing.pool.ThreadPool(processes=4) |
It is a good idea to test your application in order to determine the number of worker threads that result in the best performance.
For example, for many blocking IO tasks, you may achieve the best performance by setting the number of threads to be equal to the number of tasks themselves, e.g. 100s or 1000s.
Next, let’s look at how we might issue tasks to the thread pool.
Step 2. Submit Tasks to the Thread Pool
Once the ThreadPool has been created, you can submit tasks execution.
As discussed, there are two main approaches for submitting tasks to the thread pool, they are:
- Issue tasks synchronously.
- Issue tasks asynchronously.
Let’s take a closer look at each approach in turn.
Step 2a. Issue Tasks Synchronously
Issuing tasks synchronously means that the caller will block until the issued task or tasks have completed.
Blocking calls to the thread pool include apply(), map(), and starmap().
- Use apply()
- Use map()
- Use starmap()
We can issue one-off tasks to the thread pool using the apply() function.
The apply() function takes the name of the function to execute by a worker thread. The call will block until the function is executed by a worker thread, after which time it will return.
For example:
|
1 2 3 |
... # issue a task to the thread pool pool.apply(task) |
The thread pool provides a parallel version of the built-in map() function for issuing tasks.
For example:
|
1 2 3 4 |
... # iterates return values from the issued tasks for result in map(task, items): # ... |
The starmap() function is the same as the parallel version of the map() function, except that it allows each function call to take multiple arguments. Specifically, it takes an iterable where each item is an iterable of arguments for the target function.
For example:
|
1 2 3 4 |
... # iterates return values from the issued tasks for result in starmap(task, items): # ... |
Step 2b. Issue Tasks Asynchronously
Issuing tasks asynchronously to the thread pool means that the caller will not block, allowing the caller to continue on with other work while the tasks are executing.
The non-blocking calls to issue tasks to the thread pool return immediately and provide a hook or mechanism to check the status of the tasks and get the results later. The caller can issue tasks and carry on with the program.
Non-blocking calls to the thread pool include apply_async(), map_async(), and starmap_async().
The imap() and imap_unordered() are interesting. They return immediately, so they are technically non-blocking calls. The iterable that is returned will yield return values as tasks are completed. This means traversing the iterable will block.
- Use apply_async()
- Use map_async()
- Use imap()
- Use imap_unordered()
- Use starmap_async()
The apply_async(), map_async(), and starmap_async() functions are asynchronous versions of the apply(), map(), and starmap() functions described above.
They all return an AsyncResult object immediately that provides a handle on the issued task or tasks.
For example:
|
1 2 3 |
... # issue tasks to the thread pool asynchronously result = map_async(task, items) |
The imap() function takes the name of a target function and an iterable like the map() function.
The difference is that the imap() function is more lazy in two ways:
- imap() issues multiple tasks to the thread pool one-by-one, instead of all at once like map().
- imap() returns an iterable that yields results one-by-one as tasks are completed, rather than one-by-one after all tasks have completed like map().
For example:
|
1 2 3 4 |
... # iterates results as tasks are completed in order for result in imap(task, items): # ... |
The imap_unordered() is the same as imap(), except that the returned iterable will yield return values in the order that tasks are completed (e.g. out of order).
For example:
|
1 2 3 4 |
... # iterates results as tasks are completed, in the order they are completed for result in imap_unordered(task, items): # ... |
Now that we know how to issue tasks to the thread pool, let’s take a closer look at waiting for tasks to complete or getting results.
Free Python ThreadPool Course
Download your FREE ThreadPool PDF cheat sheet and get BONUS access to my free 7-day crash course on the ThreadPool API.
Discover how to use the ThreadPool including how to configure the number of worker threads and how to execute tasks asynchronously
Step 3. Wait for Tasks to Complete (Optional)
An AsyncResult object is returned when issuing tasks to ThreadPool the thread pool asynchronously.
This can be achieved via any of the following methods on the thread pool:
- apply_async() to issue one task.
- map_async() to issue multiple tasks.
- starmap_async() to issue multiple tasks that take multiple arguments.
A AsyncResult provides a handle on one or more issued tasks.
It allows the caller to check on the status of the issued tasks, to wait for the tasks to complete, and to get the results once tasks are completed.
We do not need to use the returned AsyncResult, such as if issued tasks do not return values and we are not concerned with when the tasks complete or whether they are completed successfully.
That is why this step in the life-cycle is optional.
Nevertheless, there are two main ways we can use an AsyncResult to wait, they are:
- Wait for issued tasks to complete.
- Wait for a result from issued tasks.
Let’s take a closer look at each approach in turn.
3a. Wait on AsyncResult objects to Complete
We can wait for all tasks to complete via the AsyncResult.wait() function.
This will block until all issued tasks are completed.
For example:
|
1 2 3 |
... # wait for issued task to complete result.wait() |
If the tasks have already completed, then the wait() function will return immediately.
A “timeout” argument can be specified to set a limit in seconds for how long the caller is willing to wait.
If the timeout expires before the tasks are complete, the wait() function will return.
When using a timeout, the wait() function does not give an indication that it returned because tasks completed or because the timeout elapsed. Therefore, we can check if the tasks completed via the ready() function.
For example:
|
1 2 3 4 5 6 7 8 9 10 |
... # wait for issued task to complete with a timeout result.wait(timeout=10) # check if the tasks are all done if result.ready() print('All Done') ... else : print('Not Done Yet') ... |
3b. Wait on AsyncResult objects for Result
We can get the result of an issued task by calling the AsyncResult.get() function.
This will return the result of the specific function called to issue the task.
- apply_async(): Returns the return value of the target function.
- map_async(): Returns an iterable over the return values of the target function.
- starmap_async(): Returns an iterable over the return values of the target function.
For example:
|
1 2 3 |
... # get the result of the task or tasks value = result.get() |
If the issued tasks have not yet completed, then get() will block until the tasks are finished.
If an issued task raises an exception, the exception will be re-raised once the issued tasks are completed.
We may need to handle this case explicitly if we expect a task to raise an exception on failure.
A “timeout” argument can be specified. If the tasks are still running and do not complete within the specified number of seconds, a multiprocessing.TimeoutError is raised.
You can learn more about the AsyncResult object in the tutorial:
Next, let’s look at how we might shutdown the thread pool once we are finished with it.
Overwhelmed by the python concurrency APIs?
Find relief, download my FREE Python Concurrency Mind Maps
Step 4. Shutdown the Thread Pool
The ThreadPool can be closed once we have no further tasks to issue.
There are two ways to shutdown the thread pool.
They are:
- Call close().
- Call terminate().
The close() method will return immediately and the pool will not take any further tasks.
For example:
|
1 2 3 |
... # close the thread pool pool.close() |
The Pool class provides the terminate() function that will close the pool and terminate all workers, even if they are running.
Threads cannot be terminated directly like processes. Therefore the terminate() method on the ThreadPool will not terminate running tasks. Instead, terminate() will operate just like the close() method.
For example:
|
1 2 3 |
... # close all worker threads pool.terminate() |
We may want to then wait for all tasks in the pool to finish.
This can be achieved by calling the join() function on the pool.
For example:
|
1 2 3 |
... # wait for all issued tasks to complete pool.join() |
An alternate approach is to shutdown the thread pool automatically with the context manager interface.
Step 4a. ThreadPool Context Manager
A context manager is an interface on Python objects for defining a new run context.
Python provides a context manager interface on the thread pool.
This achieves a similar outcome to using a try-except-finally pattern, with less code.
Specifically, it is more like a try-finally pattern, where any exception handling must be added and occur within the code block itself.
For example:
|
1 2 3 4 5 6 |
... # create and configure the thread pool with multiprocessing.pool.ThreadPool() as pool: # issue tasks to the pool # ... # close the pool automatically |
There is an important difference with the try-finally block.
The ThreadPool class extends the Pool class. As such, if we look at the source code for the multiprocessing.Pool class, we can see that the __exit__() method calls the terminate() method on the thread pool when exiting the context manager block.
This means that the pool is closed once the context manager block is exited. It ensures that the resources of the thread pool are released before continuing on, but does not ensure that tasks that have already been issued are completed first.

Further Reading
This section provides additional resources that you may find helpful.
Books
- Python ThreadPool Jump-Start, Jason Brownlee (my book!)
- Threading API Interview Questions
- ThreadPool PDF Cheat Sheet
I also recommend specific chapters from the following books:
- Python Cookbook, David Beazley and Brian Jones, 2013.
- See: Chapter 12: Concurrency
- Effective Python, Brett Slatkin, 2019.
- See: Chapter 7: Concurrency and Parallelism
- Python in a Nutshell, Alex Martelli, et al., 2017.
- See: Chapter: 14: Threads and Processes
Guides
- Python ThreadPool: The Complete Guide
- Python Multiprocessing Pool: The Complete Guide
- Python ThreadPoolExecutor: The Complete Guide
- Python Threading: The Complete Guide
APIs
References
Takeaways
You now know the life-cycle of the ThreadPool in Python.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.


Leave a Reply