ProcessPoolExecutor Quick-Start Guide
The ProcessPoolExecutor is a flexible and powerful process pool for executing ad hoc tasks in an asynchronous manner.
In this tutorial you will discover how to get started using the ProcessPoolExecutor quickly in Python.
Let's get started.
ProcessPoolExecutor in Python
The ProcessPoolExecutor provides a pool of generic worker processes.
It was designed to be easy and straightforward to use.
If multiprocessing was like the transmission for changing gears in a car, then using multiprocessing.Process is a manual transmission (e.g. hard to learn and and use) whereas concurrency.futures.ProcessPoolExecutor is an automatic transmission (e.g. easy to learn and use).
- multiprocessing.Process: Manual multiprocessing in Python.
- concurrency.futures.ProcessPoolExecutor: Automatic or "just work" mode for multiprocessing in Python.
There are four main steps in the life-cycle of using the ProcessPoolExecutor class, they are: create, submit, wait, and shutdown.
- 1. Create: Create the process pool by calling the constructor ProcessPoolExecutor().
- 2. Submit: Submit tasks and get Future objects by calling submit() or map().
- 2a. Submit Tasks with map()
- 2b. Submit Tasks with submit()
- 3. Wait: Wait and get results as tasks complete (optional).
- 3a. Wait for Future objects to Complete
- 3b. Wait for Future objects As Completed
- 4. Shutdown: Shutdown the process pool by calling shutdown().
- 4a. Shutdown Automatically with the Context Manager
The following figure helps to picture the life-cycle of the ProcessPoolExecutor class.
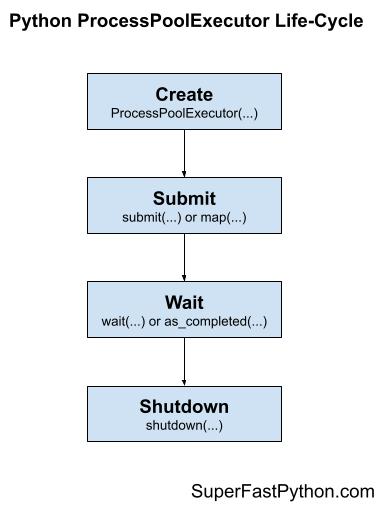
Let's take a closer look at each life-cycle step in turn.
Step 1. Create the Process Pool
First, a ProcessPoolExecutor instance must be created.
When an instance of a ProcessPoolExecutor is created it must be configured with the fixed number of processes in the pool, the method used for creating new processes (e.g. spawn or fork), and the name of a function to call when initializing each process along with any arguments for the function.
The pool is created with one process for each CPU in your system. This is good for most purposes.
- Default Total Processes = (Total CPUs)
For example, if you have 4 CPUs, each with hyperthreading (most modern CPUs have this), then Python will see 8 CPUs and will allocate 8 processes to the pool by default.
...
# create a process pool with the default number of worker processes
executor = ProcessPoolExecutor()It is a good idea to test your application in order to determine the number of processes that result in the best performance.
For example, for many computationally intensive tasks, you may achieve the best performance by setting the number of processes to be equal to the number of physical CPU cores (before hyperthreading), instead of the logical number of CPU cores (after hyperthreading).
You can specify the number of processes to create in the pool via the max_workers argument, for example:
...
# create a process pool with 10 workers
executor = ProcessPoolExecutor(max_workers=10)Step 2. Submit Tasks to the Process Pool
Once the process pool has been created, you can submit tasks for asynchronous execution.
As discussed, there are two main approaches for submitting tasks defined on the Executor parent class. They are: map() and submit().
Step 2a. Submit Tasks with map()
The map() function is an asynchronous version of the built-in map() function for applying a function to each element in an iterable, like a list.
You can call the map() function on the pool and pass it the name of your function and the iterable.
You are most likely to use map() when converting a for loop to run using one process per loop iteration.
The usage of map() assumes that your target task function takes one item from each iterable passed to the map function.
...
# perform all tasks in parallel
results = executor.map(work, items) # does not blockWhere "work" is your function that you wish to execute and "items" is your iterable of objects, each to be executed by your "work" function.
The tasks will be queued up in the process pool and executed by worker processes in the pool as they become available.
The map() function will return an iterable immediately. This iterable can be used to access the results from the target task function as they are available in the order that the tasks were submitted (e.g. order of the iterable you provided).
...
# iterate over results as they become available
for result in executor.map(work, items):
print(result)
You can also set a timeout when calling map() via the "timeout" argument in seconds if you wish to impose a limit on how long you're willing to wait for each task to complete as you're iterating, after which a TimeOut error will be raised.
...
# iterate over results as they become available
for result in executor.map(work, items, timeout=5):
# wait for task to complete or timeout expires
print(result)
Step 2b. Submit Tasks with submit()
The submit() function submits one task to the process pool for execution.
The function takes the name of the function to call and all arguments to the function, then returns a Future object immediately.
The Future object is a promise to return the results from the task (if any) and provides a way to determine if a specific task has been completed or not.
...
# submit a task with arguments and get a future object
future = executor.submit(work, arg1, arg2) # does not blockWhere "work" is the function you wish to execute and "arg1" and "arg2" are the first and second arguments to pass to the "work" function.
You can use the submit() function to issue tasks that do not take any arguments, for example:
...
# submit a task with no arguments and get a future object
future = executor.submit(my_task) # does not blockYou can access the result of the task via the result() function on the returned Future object. This call will block until the task is completed.
...
# get the result from a future
result = future.result() # blocksYou can also set a timeout when calling result() via the "timeout" argument in seconds if you wish to impose a limit on how long you're willing to wait for each task to complete, after which a TimeOut error will be raised.
...
# wait for task to complete or timeout expires
result = future.result(timeout=5) # blocksStep 3. Wait for Tasks to Complete (Optional)
The concurrent.futures module provides two module utility functions for waiting for tasks via their Future objects.
Recall that Future objects are only created when we call submit() to push tasks into the process pool.
These wait functions are optional to use, as you can wait for results directly after calling map() or submit() or wait for all tasks in the process pool to finish.
These two module functions are wait() for waiting for Future objects to complete and as_completed() for getting Future objects as their tasks complete.
- wait(): Wait on one or more Future objects until they are completed.
- as_completed(): Returns Future objects from a collection as they complete their execution.
You can use both functions with Future objects created by one or more process pools, they are not specific to any given process pool in your application. This is helpful if you want to perform waiting operations across multiple process pools that are executing different types of tasks.
Both functions are useful to use with an idiom of dispatching multiple tasks into the process pool via calling submit() in a list comprehension, for example:
...
# dispatch tasks into the process pool and create a list of futures
futures = [executor.submit(work, item) for item in items]Here, “work” is our custom target task function, "item" is one element of data passed as an argument to "work", and "items" is our source of "item" objects.
We can then pass the Future objects to wait() or as_completed().
Creating a list of Future objects in this way is not required, just a common pattern when converting for loops into tasks submitted to a process pool.
Step 3a. Wait for Futures to Complete
The wait() function can take one or more Future objects and will return when a specified action occurs, such as all tasks completing, one task completing, or one task throwing an exception.
The function will return one set of Future objects that match the condition set via the "return_when" argument. The second set will contain all of the Future objects for tasks that did not meet the condition. These are called the "done" and the "not_done" sets of futures.
It is useful for waiting on a large batch of work and to stop waiting when we get the first result.
This can be achieved via the FIRST_COMPLETED constant passed to the "return_when" argument.
...
# wait until we get the first result
done, not_done = wait(futures, return_when=FIRST_COMPLETED)Alternatively, we can wait for all tasks to complete via the ALL_COMPLETED constant.
This can be helpful if you are using submit() to dispatch tasks and are looking for an easy way to wait for all work to be completed.
...
# wait for all tasks to complete
done, not_done = wait(futures, return_when=ALL_COMPLETED)There is also an option to wait for the first exception via the FIRST_EXCEPTION constant.
...
# wait for the first exception
done, not_done = wait(futures, return_when=FIRST_EXCEPTION)Step 3b. Wait for Futures As Completed
The beauty of performing tasks concurrently is that we can get results as they become available, rather than waiting for all tasks to be completed.
The as_completed() function will return Future objects for tasks as they are completed in the process pool.
We can call the function and provide it a list of Future objects created by calling submit() and it will return Future objects as they are completed in whatever order.
It is common to use the as_completed() function in a loop over the list of Future objects created when calling submit, for example:
...
# iterate over all submitted tasks and get results as they are available
for future in as_completed(futures):
# get the result for the next completed task
result = future.result() # blocks
Note, this is different to iterating over the results from calling map() in two ways.
Firstly map() returns an iterator over objects, not over Future objects.
Secondly, map() returns results in the order that the tasks were submitted, not in the order that they are completed.
Step 4. Shutdown the Process Pool
Once all tasks are completed we can close down the process pool which will release each process and any resources it may hold.
For example, each process is running an instance of the Python interpreter and at least one thread (the main thread) that has its own stack space.
...
# shutdown the process pool
executor.shutdown() # blocksThe shutdown() function will wait for all tasks in the process pool to complete before returning by default.
This behavior can be changed by setting the "wait" argument to False when calling shutdown(), in which case the function will return immediately. The resources used by the process pool will not be released until all current and queued tasks are completed.
...
# shutdown the process pool
executor.shutdown(wait=False) # does not blockWe can also instruct the pool to cancel all queued tasks to prevent their execution. This can be achieved by setting the "cancel_futures" argument to True. By default queued tasks are not cancelled when calling shutdown().
...
# cancel all queued tasks
executor.shutdown(cancel_futures=True) # blocksIf we forget to close the process pool, the process pool will be closed automatically when we exit the main thread. If we forget to close the pool and there are still tasks executing, the main process will not exit until all tasks in the pool and all queued tasks have executed.
Step 4a. Shutdown Automatically with the Context Manager
A preferred way to work with the ProcessPoolExecutor class is to use a context manager.
This matches the preferred way to work with other resources such as files and sockets.
Using the ProcessPoolExecutor with a context manager involves using the "with" keyword to create a block in which you can use the process pool to execute tasks and get results.
Once the block has completed the process pool is automatically shutdown. Internally, the context manager will call the shutdown() function with the default arguments, waiting for all queued and executing tasks to complete before returning and carrying on.
Below is a code snippet to demonstrate creating a process pool using the context manager.
...
# create a process pool
with ProcessPoolExecutor(max_workers=10) as executor:
# submit tasks and get results
# ...
# automatically shutdown the process pool...
# the pool is shutdown at this point
This is a very handy idiom if you are converting a for loop to be executed asynchronously.
It is less useful if you want the process pool to operate in the background while you perform other work in the main thread of your program, or if you wish to reuse the process pool multiple times throughout your program.
Takeaways
You now know how to get started with the ProcessPoolExecutor in Python.
If you enjoyed this tutorial, you will love my book: Python ProcessPoolExecutor Jump-Start. It covers everything you need to master the topic with hands-on examples and clear explanations.